> For the complete documentation index, see [llms.txt](https://docs.bottalk.io/docs/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.bottalk.io/docs/text-to-speech/configure-your-project/extractor-rules.md).
# Extractor Rules
BotTalk Parser is very smart. It can analyze the website and decide what content is article text - and what is not. It makes intelligent decisions about what should be read aloud and left out (for example, photo descriptions, iframes, and tables).
If you want to adjust how BotTalk Parser makes those decisions - extracts content - you can do so by defining your own Extractor Rules.
You start by clicking **Add extractor rule button.**
Extractor Rules - BotTalk Audio CMS
For instance, this rule tells BotTalk always extract (and include in the audio edition) content inside the `span` element with the class name `extract`.
The left column describes the rules, and the right column - describes CSS selectors to which the rule should apply.
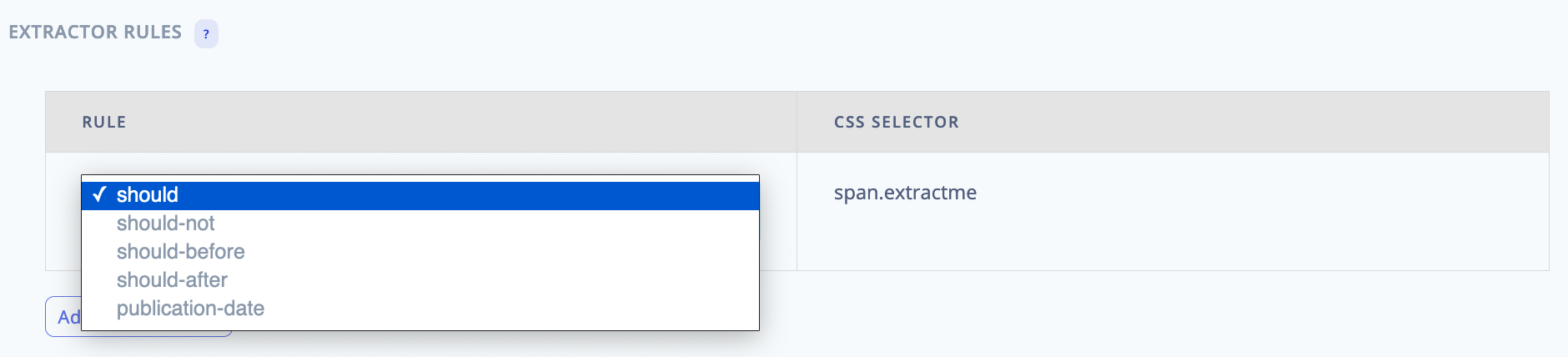
To change the rule, click on the left column. A dropdown will appear.
Extractor Rules Options - BotTalk Audio CMS
BotTalk supports the following extractor rules:
* `should`: Always speak the content
* `should not`: Never speak the content
* `should before`: Speak the content before an article begins
* `should after`: Speak the content after an article begins
* `publication date`: If your website doesn't use standard JSON-LD format, please provide a CSS selector that surrounds publication dates in your articles. We described why publication dates are essential in the previous section.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://docs.bottalk.io/docs/text-to-speech/configure-your-project/extractor-rules.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.